CANDOR: Counterfactual ANnotated DOubly Robust off-policy evaluation
Abstract
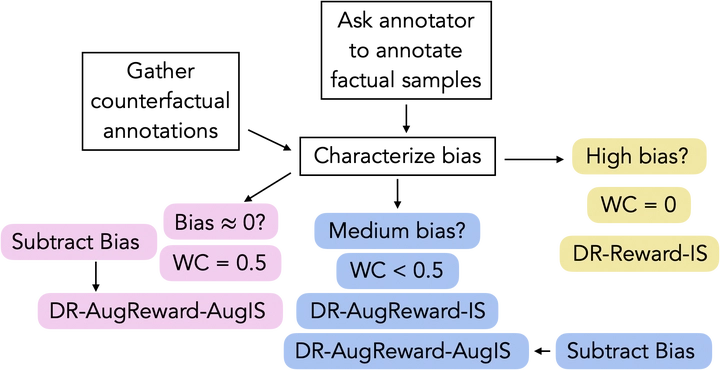
Off-policy evaluation (OPE) provides safety guarantees in high-stake domains as it can estimate the performance of a policy prior to deployment. Recent work introduced a new importance sampling (IS) estimator, which we refer to as AugIS, that incorporates expert-annotated counterfactual samples. However, IS-based estimators are known for high variance, and we show that the performance of AugIS is sensitive to low-quality annotations, which are likely to occur in realistic settings. To improve the robustness of OPE estimates in practice, we propose a family of doubly robust (DR) estimators. A DR estimator combines an estimate of the reward model (direct method, DM) with IS, and provides nice statistical guarantees. In this work, we focus on the contextual bandit setting and discuss how to incorporate counterfactual annotations into the DM part and the IS part of DR estimators under different real-life constraints. Our theories show that including counterfactual annotations does not always improve the performance of OPE estimates. We prove that incorporating highly biased annotations into the DM part can result in higher variance than the standard DR estimator. When the annotations are unbiased, using them in both the DM and IS parts is the most robust. We complete our analysis by evaluating different OPE estimators in a two-state bandit setting and in a synthetic step count simulator. We provide a practical guide on how to use annotations to improve OPE estimates under different scenarios.