Counterfactual-Augmented Importance Sampling for Semi-Offline Policy Evaluation
Abstract
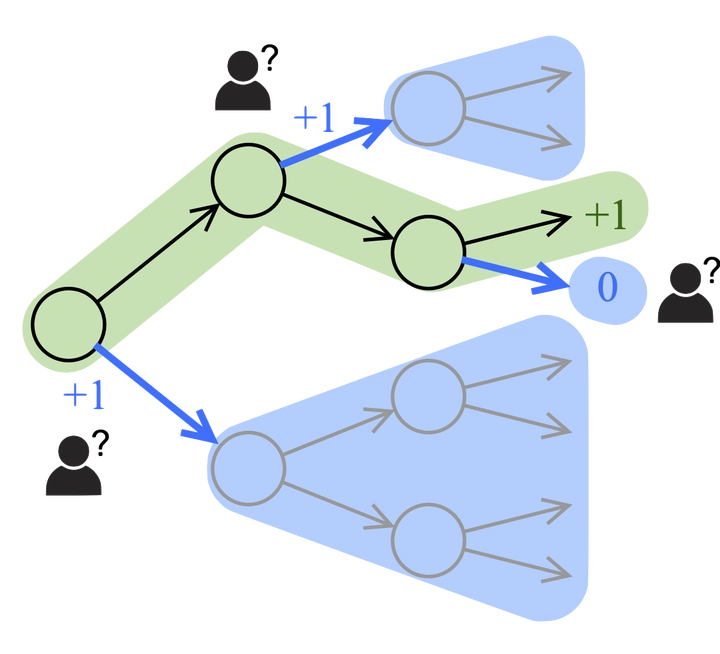
In applying reinforcement learning (RL) to high-stakes domains, quantitative and qualitative evaluation using observational data can help practitioners understand the generalization performance of new policies. However, this type of off-policy evaluation (OPE) is inherently limited since offline data may not reflect the distribution shifts resulting from the application of new policies. On the other hand, online evaluation by collecting rollouts according to the new policy is often infeasible, as deploying new policies in these domains can be unsafe. In this work, we propose a semi-offline evaluation framework as an intermediate step between offline and online evaluation, where human users provide annotations of unobserved counterfactual trajectories. While tempting to simply augment existing data with these annotations during evaluation, as we show, doing so can lead to biased results. Thus, we design a new family of OPE estimators based on a novel weighting scheme and importance sampling (IS) to incorporate counterfactual annotations without introducing additional bias. We analyze the theoretical properties of our approach, showing its potential to reduce both bias and variance compared to standard IS estimators. In a series of proof-of-concept experiments involving bandits and a healthcare-inspired simulator, we demonstrate that our approach outperforms purely offline IS estimators and is robust to noise and missingness of the annotations. Our framework, combined with principled human-centered design of annotation solicitation, can enable practical RL in high-stakes domains.